پردازش زبان طبیعی
 جمعآوری، پاکسازی و Fine-Tune کردن دیتاست
جمعآوری، پاکسازی و Fine-Tune کردن دیتاست 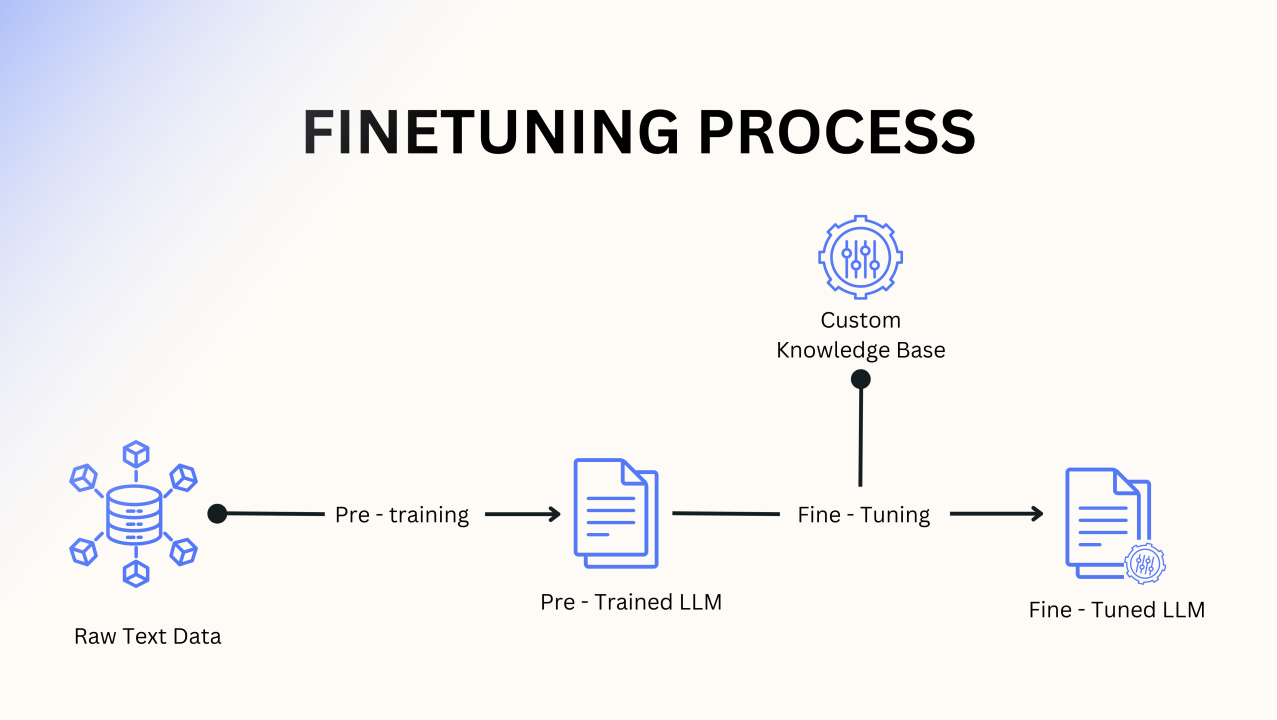

پروژه جمعآوری و Fine-Tune کردن دیتاستهای فارسی اسلامی و شیعی
این پروژه با هدف جمعآوری، سازماندهی و پردازش منابع فارسی، شامل متون علمی، اسلامی و شیعی انجام شد. هدف اصلی این پروژه ایجاد دیتاستی جامع برای فاینتیون کردن مدلهای زبانی و ساخت مدلهای زبان فارسی مبتنی بر فرهنگ و معارف اسلامی-شیعی بود. این پروژه در راستای ارتقای هوش مصنوعی زبان فارسی و بهبود تعاملات انسانی-ماشینی با تاکید بر منابع دینی و فرهنگی انجام شد.
درباره
این پروژه شامل جمعآوری متون از منابع مختلف علمی، اسلامی و شیعی مانند کتب دینی، تفاسیر، مقالات پژوهشی و متون تاریخی بود. پس از جمعآوری دادهها، فرآیند پاکسازی، برچسبگذاری و آمادهسازی برای آموزش مدلهای زبانی انجام شد. این دیتاست به عنوان یکی از پایههای توسعه مدلهای زبانی فارسی بومی مورد استفاده قرار گرفت و امکان ارائه خدمات هوش مصنوعی در حوزه زبان و فرهنگ ایرانی-اسلامی را فراهم ساخت.


-
سال
1402 - 1403
-
محل
-
-
وظیفه
جمعآوری، پاکسازی و Fine-Tune کردن دیتاست
-
ابزارها
Python, Hugging Face Transformers, NLTK
شرح
این پروژه شامل مراحل زیر است:
• جمعآوری متون فارسی از منابع دینی، علمی و تاریخی با استفاده از اسکریپتهای وبکراولینگ و ابزارهای تخصصی.
• پاکسازی دادهها برای حذف اطلاعات غیرمفید و هماهنگسازی قالب متون.
• برچسبگذاری دادهها با هدف استفاده در مدلهای زبانی خاصمنظوره.
• فاینتیون کردن مدل زبانی مانند LLAMA بر روی دیتاستهای جمعآوریشده.
• ارزیابی مدلها برای بررسی عملکرد در وظایف زبانی مختلف مانند پاسخدهی به سوالات و تولید متنهای فارسی.
• ایجاد API برای دسترسی آسان به مدلهای زبانی فاینتیونشده.
این پروژه قدمی مهم در جهت توسعه فناوری هوش مصنوعی بومی در حوزه زبان و فرهنگ ایرانی-اسلامی خواهد بود.